
作者:Steve Young, Fellow, IEEE, Milica Gasiˇ c,´ Member, IEEE, Blaise Thomson, Member, IEEE,and Jason D Williams, Member, IEEE
Abstract
统计对话管理系统是一种数据驱动的方法,无需人工构建对话管理机制,具有较好的鲁棒性。部分可观察的马尔可夫决策过程(POMDPs)具有良好的数据驱动性,但问题是完整的建模和优化计算代价巨大,甚至不可实现。在实际过程中,需对 POMDP-based 的系统近似优化求解,以下内容将对 POMDP-based 的系统的领域现状做一个综合介绍。
1. Introduction
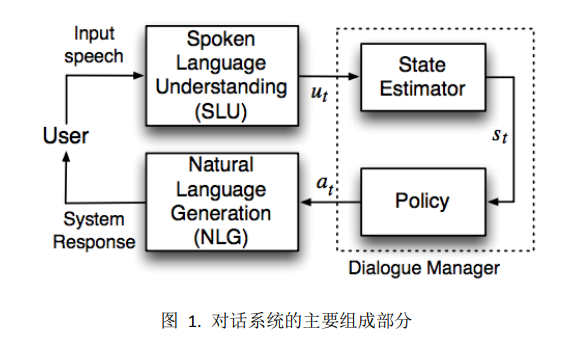
传统的 SDS 的主要组成部分如下图所示。口语理解模块(SLU)将语言转换成抽象语义表示,即用户对话行为 𝑢𝑡,而后系统更新其内部状态 𝑠𝑡,然后系统通过决策规则 𝑎𝑡 = 𝜋(𝑠𝑡)确定系统行为,最后语言生成模块(NLG)将系统行为 𝑎𝑡 转化为自然语言字符串。其中,状态变量 𝑠𝑡 包含跟踪对话过程的变量,以及表示用户需求的属性值(又称为 slots)。在传统对话系统中,决策规则是通过流程图的方式实现的,图中的结点表示状态和行为,而边则表示用户输入。
新型的对话管理系统基于部分可观察的马尔可夫决策过程(POMDPs),该方法假定对话过程是马尔可夫决策过程,也就是说,对话初始状态是 𝑠0, 每一个后续状态用转移概率来表示:𝑝(𝑠𝑡 |𝑠𝑡−1, 𝑎𝑡−1)。状态变量 𝑠𝑡 是无法直接观察到的,它代表了对用户需求理解的不确定程度。系统把 SLU 的输出看作是一个带噪音的基于用户输入的观察值,这个观察值的概率为 𝑝(𝑜𝑡 |𝑠𝑡),这里的转移概率和生成概率用恰当的随机统计模型表示,又称为对话模型 M,而每个步骤中采取哪个行动则由另一个随机模型控制,该模型称之为对话策略 P。 在对话过程中,每一步还需要一个回报函数来体现理想中的对话系统特性。对话模型 M 和对话策略 P 的优化是通过最大化回报函数的期望来实现的,该过程可以通过直接用户交互在线训练,也可以利用离线的语料库训练。详见下图。

然而在实践中运用 POMDP 并不容易,有许多实际问题需要解决。SDS 的状态行为空间巨大,求解这个空间需要复杂的算法和软件。实时的贝叶斯推理也非常难,完整的 POMDP 的学习策略是不可实现的,因此必须利用近似法求解。优化基于 POMDP 的 SDS 的最直接方式是通过直接用户对话。但是,通常难以找到足够数量的用户帮助训练系统,所以实践中常常通过用户模仿器的方式来对参数模型进行优化。
2. PARTIALLY OBSERVABLE MARKOV DECISION PROCESSES
部分可观察的马尔可夫决策过程用一个多元组(S, A, T, R, O, Z, 𝛾, 𝑏0)表示,其中 S 是状态集;A 是行为集合;T 表示转移概率 𝑃(𝑠𝑡 |𝑠𝑡−1, 𝑎𝑡−1); R 是回报的期望值;O 是观测值集合;Z 代表观测概率 𝑃(𝑜𝑡 |𝑠𝑡 , 𝑎𝑡−1 ); 𝛾 是几何衰减系数,其值在 0-1 之间;𝑏0 是置信状态的初始值。
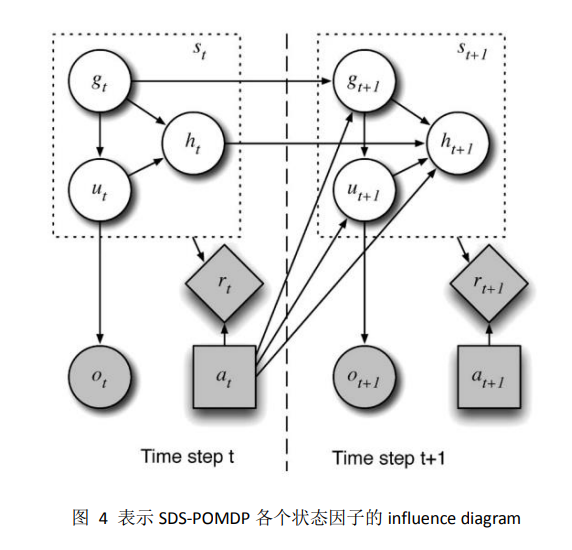
POMDP 的过程如下:在每一个过程中,真实世界是一个无法观察的状态 𝑠𝑡。因为 𝑠𝑡 是未知的,变量置信状态 𝑏𝑡 表示所有可能状态的分布,𝑏𝑡(𝑠𝑡)表示处在某个特定状态 𝑠𝑡 的概率。系统基于 𝑏𝑡 选择行为 𝑎𝑡,得到一个激励值 𝑟𝑡,然后转化到状态 𝑠𝑡+1,这里 𝑠𝑡+1 仅仅依赖于 𝑠𝑡 和 𝑎𝑡。然后系统得到一个观察值 𝑜𝑡+1,该值依赖于 𝑠𝑡+1 和 𝑎𝑡。这个过程如图所示

但问题是通用的 POMDP 方法复杂度高,难以大规模的应用到实用对话系统。即使中小型规模,其涉及的状态、行为、和观察值很容易达到 1010 量级。穷举 𝑃(𝑠𝑡+1|𝑠𝑡 , 𝑎𝑡)是不可实现的,因此,直接优化更新置信状态优化回报函数并不可行。通常情况下,我们需要简化模型近似求解。接下来我们将详细讨论。
3. BELIEF STATE REPRESENTATION AND MONITORING
本小节集中讨论图 2 中对话系统模型 M。实用 SDS 中,状态必须包含三种不同类型的信息:用户的目标 𝑔𝑡 , 用户的真实意图 𝑢𝑡,以及对话历史 ℎ𝑡。用户目标包含需要完成任务所有信息,用户真实意图是指用户实际想表达的意图而非系统识别出的意图,对话历史跟踪之前的对话流。由此,对话中的一个状态包含三个因子:st = (gt, ut, ht)
引入条件独立性假设以后,该过程可以表示为下图。将状态分解成以上三个因子可以对状态转移矩阵进行降维,同时也减少了系统的条件依赖性。
虽然状态因子模型极大的简化了 POMDP 模型的复杂度,但是它仍旧复杂,难以在实际的系统中应用。因此还需要进一步近似化处理,通常有两种常用技术:
- N-best 方法,包括剪枝和重组
- 贝叶斯网络法
4. POLICY REPRESENTATION AND REINFORCEMENT LEARNING
策略模型 P 提供了置信状态 b 和系统行为 a 的映射。我们的目标是寻找一个最优的策略最大化对话回报函数的综合期望。
有五种常用的方法来优化策略:
- planning under uncertainty
- value iteration
- Monte-Carlo 优化
- 最小平方策略迭代(LSPI)
- natural actor-critic (NAC).
这五种方式常常应用在 end-to-end 的对话系统中。除此之外,还有 Q-learning 和 SARSA 等方法。
没看懂,摆烂了
5. USER SIMULATORS
直接从语料库中学习对话策略存在很多问题,比如收集数据中的状态空间可能与策略优化数据不同。另外,这种方式无法在线互动学习。因此我们可以构建一个用户模拟器,让这个模拟器与对话系统直接进行互动。用户模拟器不仅仅可以用来学习对话系统,也可以用它来评估对话系统。
6. DIALOGUE MODEL PARAMETER OPTIMISATION
在 POMDP 中,对话系统的完整模型由两组参数组成:具有参数 τ 的对话模型 M,其中包括用户、观察和转移概率分布;以及具有参数 θ 的策略模型 P。大多数当前的 POMDP 开发都集中在策略优化和 θ 参数上,而对话模型和 τ 参数则经常是手工制作的。虽然手工制作对话模型可能看起来不太令人满意,但在许多情况下,对话设计师将对参数应该在哪里具有强烈先验知识。例如,在许多应用程序中,假定用户目标在整个对话过程中保持不变是合理的。
因此,在 POMDP 中,需要优化两组参数:对话模型 M 中的 τ 参数和策略模型 P 中的 θ 参数。尽管大多数研究都集中在策略优化上,但手工制作对话模型仍然是一种常见且有效的方法,并且可以根据应用程序和领域特定知识进行调整。
7. FAST TRAINING AND USER ADAPTATION
在 POMDP 中,对于一个真实世界的口语对话系统,策略优化需要进行 O(10^5)个训练对话,这个数量太大了,无法直接与人类用户进行交互。因此,目前的策略优化依赖于与用户模拟器的交互。这些模拟器需要高度复杂,并且不容易构建。此外,使用模拟用户训练出来的策略会偏向于这些模型所包含的特定行为。
因此,在 POMDP 中,快速训练和用户适应是非常重要的问题。目前有一些方法可以加速策略优化过程,并且可以通过在线学习算法来实现与真实用户的交互。例如,在线学习算法可以使用增量式方法来更新策略,并根据代理与真实用户交互时获得的奖励信号进行调整。
8. SYSTEMS AND APPLICATIONS
前面的几个小节讲述了统计对话系统的几个主要模块,其相关的技术在随着时间进步完善。尽管在商业上推广这些技术有一定的难度,但是在具体的场景中已有一定范围应用。这里我们简单的提几个基于 POMDP 框架的对话系统。
这些系统大多都是非正式的 inquiry 系统,包括语音呼叫(Janarthanam et al., 2011),旅游信息(Thomson & Yong, 2010),日程安排(Kim & Lee, 2007)和汽车导航(Kim et al., 2008)等。POMDP 也可应用于基于命令控制的系统,如通过多模接口控制家电(Williams, 2007)。
POMDP 曾在 CMU 举办的“Let’s Go”竞赛任务中被应用,其为 Pittsburgh 区域的居民播报非忙时段的公交车信息(Thomson et al., 2010)。在该应用中,用户可能从多种不同的手机装置来电,且通话环境通常有噪音,结果显示,基于 POMDP 的系统明显优于传统系统(Black et al., 2011)。
没啥用,搬一下原文
9. EVALUATION AND PERFORMANCE
在语音和自然语言处理领域,大多数数据驱动任务的评估方法都已经建立。但是,对于口语对话系统的评估需要与用户进行交互,因此比较困难。
目前,有几种方法可以评估口语对话系统的性能。其中一种方法是使用人类评估员来评估系统的性能,并根据其反馈来调整系统。另一种方法是使用自动评估指标来衡量系统的性能,例如识别准确率、理解准确率、策略成功率等。
10. HISTORICAL PERSPECTIVE
在口语对话系统中使用 POMDP 的第一篇论文可以追溯到 2000 年的 Roy 等人和 2001 年的 Zhang 等人。然而,在此之前,一些关键思想已经被探索。将对话管理视为可观察马尔可夫决策过程(MDP)并通过强化学习优化策略的想法归功于 Levin 和 Pieraccini。其他人很快就对这项工作进行了开发。然而,在明显缺乏任何明确表示不确定性或不完整信息的显式模型时使用 MDP 方法失去了动力。
搬原文
11. CONCLUSIONS
本文对对话系统的领域研究现状做了一个整体介绍。对话系统的核心问题是处理多轮交互,让人机之间的互动高效、自然、智能。在本文中我们涉及了对话系统的主要任务模块,并做了简单的概述,同时指出了对话系统所面临的问题和挑战。我们还介绍了对话系统的演进历史及其应用实例,并从口语交流、多模交互和对话管理方面介绍了该领域的研究趋势。接下来,本文详细介绍了 POMDP 统计对话管理器的相关技术及领域现状,同时也指出了其中的问题及面临的挑战。
总算读完了,虽然很多东西都没看懂,但还是学到了一些东西的。以后还是得好好看看数学公式。
勉强完成目标,再接再厉。
附上一些参考资料:111
再附上一个知乎大佬 heaven 的强化学习专栏:强化学习轻松入门