
作者:Tsung-Hsien Wen, Milica Gašic, Nikola Mrkši ´ c, Lina M. Rojas-Barahona, ´Pei-Hao Su, Stefan Ultes, David Vandyke, Steve Young
Abstract
摘要介绍了一种基于神经网络的端到端可训练对话系统,可以通过文本输入和输出进行训练。同时,还提出了一种新的收集面向任务对话数据的方法,基于一种新颖的 Wizard-of-Oz 框架。这种方法使我们能够轻松地开发对话系统,而不需要过多地假设所涉及的任务。结果表明,在餐厅搜索领域,该模型可以与人类主体自然交谈,并帮助他们完成任务。
1. Introduction
这篇论文的简介部分介绍了当前开发任务导向对话系统所面临的挑战,以及现有方法所存在的问题。通常情况下,开发这种对话系统需要创建多个组件,并且通常需要大量手工制作或获取标记数据集并为每个组件解决统计学习问题。本文提出了一种新的方法,即基于神经网络的端到端可训练对话系统,可以通过文本输入和输出进行训练,并且使用一种新颖的 Wizard-of-Oz 框架收集面向任务对话数据。该方法使我们能够轻松地开发对话系统,而不需要过多地假设所涉及的任务。
2. Model
模型将对话是为一个序列到序列的映射问题(以一个序列到序列的架构为模型),并添加了对话历史(以一个信念追踪为模型),如图所示。每个循环中,系统把来自用户的序列块当做输入,然后把它转换到两个内部组件中:一个由意图网络生成的分布式组件和一个在由一系列信念追踪器生成的信念状态组成的槽值对上的概率分布。然后数据库操作器在信念状态中选择最可能的值来形成一个面向 DB 的查询语句,然后就是查询结果,随后意图组件和信念状态被策略网络转化组合成一个单向量来表示下一个系统动作。然后使用该系统动作向量对响应生成所需的系统输出令牌。最后系统响应是通过用数据库词目的真实值来替换骨架句子结构来生成的。
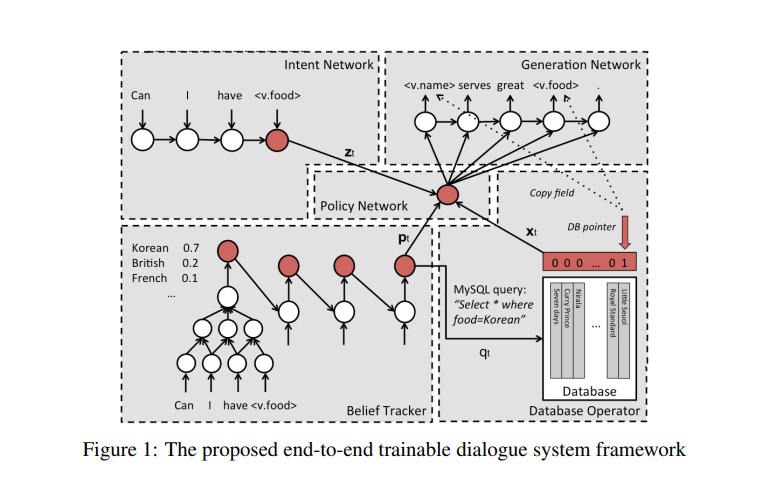
2.1 Intent Network
意图网络是该论文模型的中间层之一,用于将用户输入的自然语言序列编码为分布式向量表示。它可以被视为序列到序列学习框架中的编码器,其工作是在每个时间步骤 t 将输入令牌序列 wt0,wt1,…,wtN 编码为分布式向量表示 zt。通常使用长短时记忆(LSTM)网络作为意图网络,并将最后一个时间步骤的隐藏层 zNt 作为表示。此外,也可以使用卷积神经网络(CNN)来代替 LSTM 来编码句子。
2.2 Belief Trackers
这个部分又被称作是 Dialogue State Tracking (DST),是 task-oriented spoken dialogue system 的核心部件。
这个组件的输入时用户的输入,输出是一个 informable slot 和 requestable slot 的概率分布,这里的 informable slot 是指 food type,price range(以订餐为例),用来约束数据库中的查询,requestable slot 是指 address,phone,postcode 等一些可以被询问的值。这里会定义一个针对具体任务的知识图谱,来表示这些 slot 之间的关系,每个 slot 都会定义一个 tracker,tracker 的模型如图所示,包括一个 CNN 特征提取模块和一个 Jordan 型的 RNN 模块 (recurrence from output to hidden layer),CNN 不仅仅对当前的输入进行处理,还对上一轮的机器响应进行处理,综合起来作为 RNN 的输入。

2.3 Database Operator
数据库查询的输入来自于 Belief Trackers 的输出,即各种 slot 的概率分布,取最大的那个作为数据库的输入,进行查询,获取到相应的值。
2.4 Policy Network
这个组件是像一个胶水,起到粘合其他上面三个组件的作用。输入是上面三个组件的输出,输出是一个代表系统动作的向量。
2.5 Generation Network
这一模块本质上是一个语言模型,在 Policy Network 的输出的系统动作下,生成相应的响应,再经过一些处理返回给用户。这里的处理主要是将响应中的 slot,比如 s.food 还原成真实的值。生成部分用简单的 LSTM-LM 可以做,用 Attention Generation Model 也可以做,效果会更好。
3. Wizard-of-Oz Data Collection
Wizard-of-Oz 数据收集是该论文提出的一种用于收集特定领域对话数据的方法。在该方法中,人类操作员扮演对话系统,与用户进行交互,并记录用户的输入和系统响应。这种方法可以用于收集特定领域的任务导向对话数据,以便训练和评估任务导向对话系统。
4. Empirical Experiments
Training
作者通过两个阶段的训练过程来训练提出的模型。第一阶段是训练 Belief Tracker 参数 θb,使用交叉熵误差计算跟踪器标签 yts 和预测 pts 之间的误差。第二阶段是使用强化学习方法训练策略网络和值函数网络,并将 Belief Tracker 作为输入馈送到策略网络中。
评估摆烂了,直接上链接 https://arxiv.org/pdf/1604.04562.pdf
5. Conclusions and Future Work
作者指出,他们提出的模型在 Wizard-of-Oz 数据集上取得了很好的性能,但仍存在一些局限性。例如,该模型只能处理文本输入,无法直接处理嘈杂的语音识别输入,并且无法在不确定时询问用户进行确认。此外,该模型还需要更多的实验来验证其在更大和更广泛领域中的可扩展性。
论文里的数学公式完全看不懂,不关注细节,只看懂了大概,我大抵是个废物罢 😭
上周烦心事比较多,没更新 blog。这周总算能静下心来好好学一会了,缓解焦虑最好的办法确实是学习一些自己感兴趣的东西,总之看完这篇论文,心里确实好受一点了。
希望这周能再看一篇论文 chatpdf 确实好用,可惜收费了 😇
最后附上一篇知乎 weizier 大佬的文章:NLP 的巨人肩膀